Regresión lineal
1 La regresión lineal
La Regresión Lineal es uno de los modelos fundamentales y más utilizados en Machine Learning. Su objetivo es modelar la relación entre una o más variables de entrada (predictores) y una variable de salida continua.
Conceptualmente, la función de este modelo consiste en dibujar un objeto geométrico plano que actúe como un puente para cruzar a través de nuestra nube de datos reales, esto significa que se adapte mejor a ellos. La forma exacta de este objeto dependerá exclusivamente de la cantidad de dimensiones (variables) con las que estemos trabajando:
- En 2 Dimensiones (1 variable de entrada): El modelo genera una línea recta. El objetivo es ajustar la inclinación y la altura de esa recta para que pase lo más cerca posible de los puntos de datos esparcidos en un plano bidimensional.
- En 3 Dimensiones (2 variables de entrada): Al añadir una variable más, la recta deja de ser suficiente. El modelo se transforma y genera un plano bidimensional flotando en un espacio tridimensional.
- En 4 o más Dimensiones (3 o más variables de entrada): Cuando entramos en el terreno de la alta dimensionalidad, el modelo genera lo que matemáticamente llamamos un hiperplano. Visualmente es imposible de imaginar para la mente humana, pero algebraicamente se comporta exactamente igual que la recta o el plano.
La meta de la regresión lineal es encontrar la forma exacta que mejor se adapte a los puntos.
2 Función hipótesis
La función hipótesis contiene una serie de parámetros que ajustados a los datos construyen el modelo.
\[f_{w,b}(x) = w_1x_1 + w_2x_2 + w_3x_3 + \dots + w_nx_n + b\]
Es lo mismo que representar así:
\[f_{w,b}(x) = \left( \sum_{i=1}^{n} w_i x_i \right) + b\]
- Cada \(w_i\) es el “control de volumen” de su característica (\(x_i\)): Si mantienes fijas todas las demás características y aumentas la característica \(x_i\) en una unidad, la predicción final cambiará exactamente en la cantidad que dicte el peso \(w_i\).
- El sesgo \(b\) es el “punto de partida”: Si te llega un dato donde absolutamente todas las características valen cero (\(x_1 = 0, x_2 = 0, \dots\)), la predicción del modelo no se anula por completo, sino que toma el valor de la constante \(b\).
Computacionalmente se trabaja con vectores:
Definimos las características (\(x\)) y los pesos (\(w\)) como dos vectores columna en un espacio de \(n\) dimensiones:
\[W = \begin{bmatrix} w_1 \\ w_2 \\ \vdots \\ w_n \end{bmatrix}, \quad X = \begin{bmatrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{bmatrix}\]
Para multiplicar estos dos vectores correctamente (elemento por elemento y luego sumarlos), debemos transponer el vector de pesos \(W\) (convertirlo de columna a fila) y realizar un producto escalar (o producto punto) con el vector \(X\).
La función hipótesis compacta se define entonces como:
\[f_{W,b}(X) = W^T X + b\]
Supongamos que tenemos que tasar e precio de una vivienda usando tres características (\(n=3\)):
- \(x_1\): Los metros cuadrados de la vivienda.
- \(x_2\): El número de habitaciones.
- \(x_3\): La antigüedad de la casa (en años).
Supongamos que nuestro algoritmo de Machine Learning ya entrenó con miles de casas de ejemplo y fijó estos parámetros:
Vector de Pesos (\(W\)): \[W = \begin{bmatrix} w_1 \\ w_2 \\ w_3 \end{bmatrix} = \begin{bmatrix} 2000 \\ 15000 \\ -3000 \end{bmatrix}\]
Sesgo (\(b\)):
\[b = 50000\]
Nos piden valorar una casa con las siguientes especificaciones:
- 120 metros cuadrados
- 3 habitaciones
- 10 años de antigüedad.
\[X = \begin{bmatrix} x_1 \\ x_2 \\ x_3 \end{bmatrix} = \begin{bmatrix} 120 \\ 3 \\ 10 \end{bmatrix}\]
\[W^T X = \begin{bmatrix} 2000 & 15000 & -3000 \end{bmatrix} \begin{bmatrix} 120 \\ 3 \\ 10 \end{bmatrix}\]
\[W^T X = (2000 \cdot 120) + (15000 \cdot 3) + (-3000 \cdot 10)\]
\[f_{W,b}(X) = 255000 + 50000 = 305000\]
El modelo predice que el valor justo de mercado para esta casa es de 305 000€.
En realidad este modelo aplica una suma ponderada más un valor adicional (la constante)
3 La función de coste en la regresión lineal
En el caso de la regresión lineal se utiliza la función de coste del error cuadrático medio (MSE). Esta función de coste se representa así:
\[J(W,b) = \frac{1}{2m} \sum_{i=1}^{m} \left( f_{W,b}(X^{(i)}) - Y^{(i)} \right)^2\]
- La \(m\) en el denominador: Como se suman los errores de \(m\) elementos, al dividir entre \(m\) se está calculando el promedio (el error cuadrático medio). Esto mantiene el coste en la misma escala sin importar el tamaño de la base de datos.
- El número \(2\) en el denominador: Se coloca ahí por pura conveniencia matemática de cara a las derivadas. Cuando el algoritmo calcule el gradiente y derive esta función respecto a los parámetros, el exponente cuadrático \((2)\) bajará multiplicando y se cancelará perfectamente con este \(1/2\) (\(\frac{2}{2} = 1\)).
3.1 El Flujo del Modelo
Tenemos un modelo que recibe como entrada un vector de características (\(X\)), el cual se multiplica mediante un producto escalar (\(W^T X\)) por un vector de pesos (\(W\)) y se le suma un sesgo (\(b\)). Esto genera una salida u objetivo estimado (\(Y_{\text{pred}}\)).
Lo que necesitamos es calcular hacia dónde y con qué intensidad hay que ajustar cada uno de los pesos (\(W\)) y el sesgo (\(b\)) respecto a la función de error cuadrático \(J\).
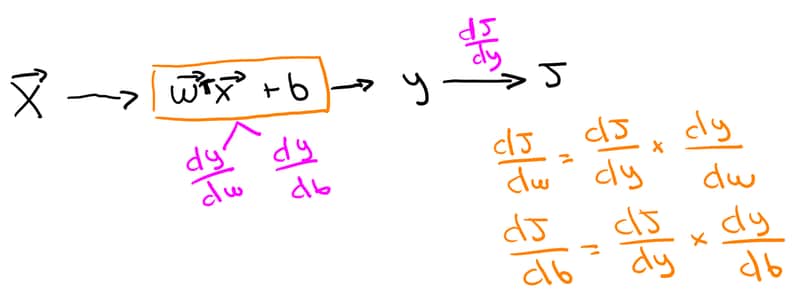
Para saber cómo ajustar los parámetros, calculamos las derivadas parciales de la función de error respecto a cada uno de ellos descomponiendo el problema paso a paso:
Para el vector de pesos (\(W\)): \[\frac{\partial J}{\partial W} = \frac{\partial J}{\partial Y_{\text{pred}}} \cdot \frac{\partial Y_{\text{pred}}}{\partial W}\]
Para el sesgo (\(b\)): \[\frac{\partial J}{\partial b} = \frac{\partial J}{\partial Y_{\text{pred}}} \cdot \frac{\partial Y_{\text{pred}}}{\partial b}\]
El cálculo de cada una de estas derivadas es muy sencillo si resolvemos cada eslabón por separado:
El error puro: La derivada de la función error respecto a la predicción es simplemente la diferencia con la realidad: \[\frac{\partial J}{\partial Y_{\text{pred}}} = (Y_{\text{pred}} - Y)\]
La derivada respecto a los pesos: Como la ecuación es \(Y_{\text{pred}} = W^T X + b\), si derivamos respecto a \(W\), la constante \(b\) desaparece y nos queda la característica: \[\frac{\partial Y_{\text{pred}}}{\partial W} = X\]
La derivada respecto al sesgo: Si derivas la misma ecuación respecto a \(b\), el bloque \(W^T X\) desaparece y la derivada de \(b\) es simplemente uno: \[\frac{\partial Y_{\text{pred}}}{\partial b} = 1\]
3.2 Ejemplo Práctico Vectorial (3 Características)
Imagina que queremos predecir el precio de una casa en base a \(n=3\) características:
- \(x_1 = 2\) (Número de habitaciones)
- \(x_2 = 3\) (Número de baños)
- \(x_3 = 1\) (Garajes)
El objetivo real (\(Y\)) de la casa en el mercado es \(Y = 100\) (en miles de euros).
3.2.1 1. Inicialización de Vectores
Definimos nuestro vector de entrada (\(X\)) y unos parámetros iniciales aleatorios (\(W\) y \(b\)):
\[X = \begin{bmatrix} 2 \\ 3 \\ 1 \end{bmatrix}, \quad W = \begin{bmatrix} 10 \\ 10 \\ 10 \end{bmatrix}, \quad b = 5\]
3.2.2 2. Forward Propagation
Calculamos la predicción del modelo realizando el producto escalar fila por columna:
\[W^T X = \begin{bmatrix} 10 & 10 & 10 \end{bmatrix} \begin{bmatrix} 2 \\ 3 \\ 1 \end{bmatrix} = (10 \cdot 2) + (10 \cdot 3) + (10 \cdot 1)\]
\[W^T X = 20 + 30 + 10 = \mathbf{60}\]
\[Y_{\text{pred}} = 60 + 5 = \mathbf{65}\]
3.2.3 3. Backward Propagation (Cálculo de Gradientes)
Calculamos la intensidad del error y la aplicamos a las fórmulas derivadas para obtener el gradiente del vector de pesos (\(\nabla_W J\)) y del sesgo (\(\frac{\partial J}{\partial b}\)):
\[\text{Error} = (Y_{\text{pred}} - Y) = 65 - 100 = \mathbf{-35}\]
\[\nabla_W J = (Y_{\text{pred}} - Y) \cdot X = -35 \cdot \begin{bmatrix} 2 \\ 3 \\ 1 \end{bmatrix} = \begin{bmatrix} -70 \\ -105 \\ -35 \end{bmatrix}\]
\[\frac{\partial J}{\partial b} = -35\]
3.2.4 4. Actualización de Parámetros
Utilizando una tasa de aprendizaje \(\alpha = 0.1\), aplicamos el descenso de gradiente para actualizar los valores de forma masiva:
\[W_{\text{nuevo}} = W_{\text{actual}} - \alpha \cdot \nabla_W J\]
\[W_{\text{nuevo}} = \begin{bmatrix} 10 \\ 10 \\ 10 \end{bmatrix} - 0.1 \cdot \begin{bmatrix} -70 \\ -105 \\ -35 \end{bmatrix} = \begin{bmatrix} 10 \\ 10 \\ 10 \end{bmatrix} - \begin{bmatrix} -7 \\ -10.5 \\ -3.5 \end{bmatrix}\]
\[W_{\text{nuevo}} = \begin{bmatrix} 10 - (-7) \\ 10 - (-10.5) \\ 10 - (-3.5) \end{bmatrix} = \begin{bmatrix} 17 \\ 20.5 \\ 13.5 \end{bmatrix}\]
Para el sesgo:
\[b_{\text{nuevo}} = 5 - 0.1 \cdot (-35) = \mathbf{8.5}\]